FAIR Data and Research Data Lifecycle
Author: Carolin Odebrecht
The FAIR Guiding Principles (Wilkinson et al. 2016) state that (meta)data should be Findable, Accessible, Interoperable, and Reusable. FAIR represents the interface between the high-level goals of research integrity and openness on the one hand and the process model research data lifecycle, on the other, developed within the context of research data management. This wiki section will explain the connections between the values and the practices as well as provide examples from the CLS domain of addressing both kinds of issues.
The FAIR Guiding Principles provide a clear goal for data (and software) which refers directly to our good scientific practices providing the fundament of research integrity: “Research integrity is crucial to preserving the trustworthiness of the research system and its results” (ALLEA - All European Academies 2023).
FAIR data can be interpreted as the overarching goal of research data management: “Research data management is an explicit process covering the creation and stewardship of research materials to enable their use for as long as they retain value” (DCC digital curation glossary, entry “Research Data Management”). Research data life cycle is an established model of how research data management should be implemented: it is a process model that sets main steps of data handling in a temporal and / or functional relation (Cox and Tam 2018).
Take-home message: The FAIR Guiding principles specify the high-level goals of research integrity and openness by relating them to the domain of (meta)data, for which the research data lifecycle provides an implementation process model.
Research Data Lifecycle
The research data lifecycle model focuses on the main tasks of data handling that pertain to the entirety of the research process. Thus, it relates the general goals of attaining FAIR data to concrete tasks, which researchers confront when implementing their individual schemes.
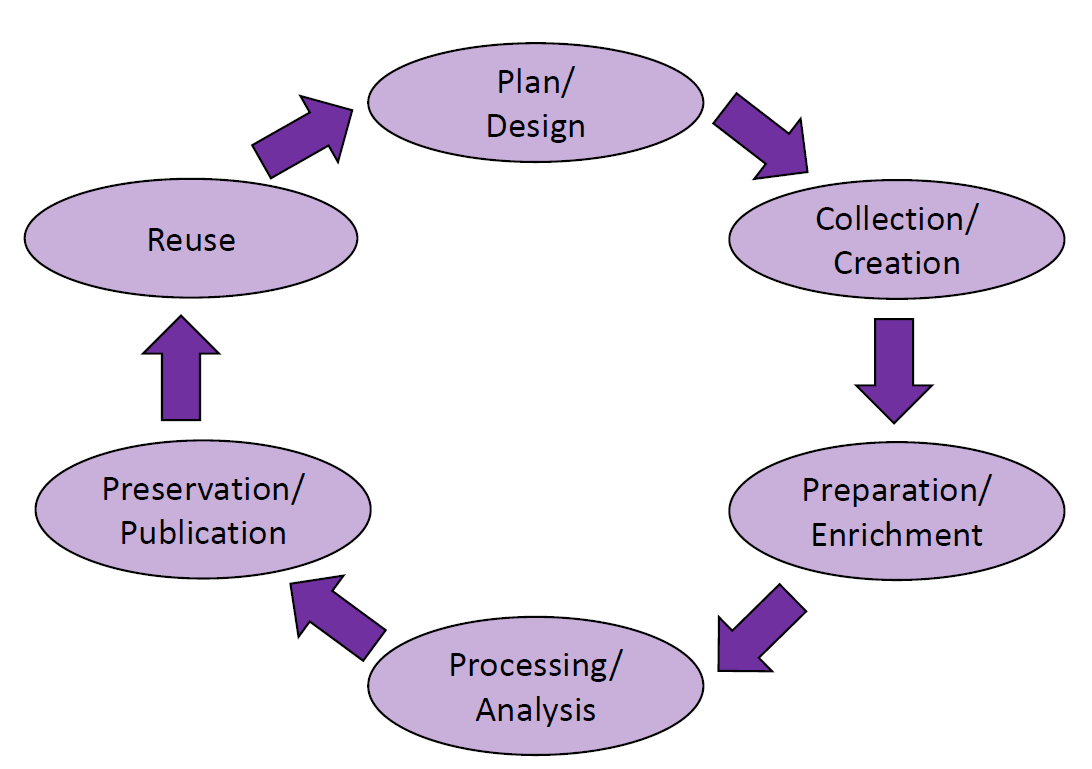
Typically, the research process starts with planning and designing that establishes the goals and parameters of corpus design, data management, and research questions and methods alongside devising a strategy for the publication of research results and data (Section Planning and Designing Data). These decisions serve as a blueprint for data collection and / or creation (Section Creating and Collecting Data), followed by data preparation and enrichment (Section Preparing and Enriching Data. The analysis stage is closely connected to and evaluated with a view to the research goals (Section Exploring and Analysing Data). For a sustainable conclusion of the research, it is also necessary to back up, document, and publish all the data generated in the process (Section Preserving and Publishing Data). References to software and applications that are necessary to address each step should be considered as well. Finally, published data becomes a subject of reuse practices (Section Reusing Data).
Take-home message: The research data lifecycle provides a blueprint for planning and implementing a research (data) project in keeping with the FAIR Guiding Principles and the values of the openness and reproducibility of research results.
Connection of CLS data to FAIR, Research Integrity, and Research Data Lifecycle
Connecting these abstract goals, models, and guidelines to concrete research situations presents a major challenge both for researchers and institutions, in whose broader context the former operate. In the context of CLS, these challenges can be broken down into three fundamental questions:
- How can planning and design effectively address CLS-specific requirements?
- Which CLS-specific parameters for data are needed to be considered during implementation?
- Which publication strategies enable the research community to reuse CLS data according to the FAIR Guiding Principles?
In order to address these questions and to foster adaptability and knowledge transfer, we provide this wiki with CLS examples for each step of the research data lifecycle. In addition, disciplines typically develop domain-specific requirements concerning such overreaching notions as accessibility or interoperability. “Accessibility” may refer to human interaction with data (searching for data using meta-search engines) or to machine-accessible interfaces that enable automatic data crawling. For “Interoperability”, domain-specific best practices in selecting formats, schemas, and applications need to be considered (and documented).
Take-home message: The implementation of the FAIR Guiding Principles requires an application of meta-requirements that pertain to all disciplines working with digital data to unique research projects. This application process requires interpretation in this sense that domain-specific characteristics of data, research procedures, and output need to be defined and implemented in each step of the research data lifecycle.
Documentation
Documentation is a method that explictely protocols the steps of the research data lifecycle and and the measures for compliance with good scientific practice. Documentation is therefore connected to every Section in this wiki and can be implemented in several forms connected to the documentation goal and addresses, e.g.:
- Data handbook
- Data management plan
- Data collection protocol
- Metadata
- README